
tcp_sack, useless overhead ?
Posted on July 28, 2017 • 4 minutes • 818 words • Suggest Changes
I recently learned about tcp_sack while I certainly don’t understand every detail of this feature, its clear it should be a huge help in cases where packets (in TCP protocol) are dropped and latency is relative high. From my basic understanding, when sending TCP protocol packages, every package has a number (sequence) when tcp_sack is enabled on both client/server. Tcp_sack will be able to respond to the server which range has been dropped. When _tcp_sack _is not enabled, the client will only send the “last” sequentially received packet, and everything has to be resend from the last received packet.
Eg : packet 1-10 are received, packet 11-14 are lost, packet 15-35 are received; **with **_tcp_sack _: client will tell that it received packet 10 and packet 15, and hence the server can respond with packets 11-14. **Without **_tcp_sack _: client will tell that it received up till packet 10, and hence the server will have to resend packets 11-35
In all the distro’s I could get my hands on (Centos, Debian, Ubuntu, …), it was on by default! The question however, is how many packets are commonly dropped and does communication even have “high” latency ? At what cost does tcp_sack come ? I found little data about resource consumption by this feature, but since its “on-by-default” I assume its trivial. I did however find this article that claimed on a ~4MB file, with emulated connection, that tcp_sack actually made the transfer slower (above 2 min vs below 2 min with tcp_sack for a 1% loss) That seems to defeat he purpose of tcp_sack all together. I am not as interested in these situations, as my environment is local servers talking to each other, I don’t really care that much if they go faster or slower in packet loss situations, as its a red flag is latency or packet loss happens all together.
I copied over a random payload to check if the parameter has any influence on the time spend to transfer.
tcp_sack enabled
This is our baseline, normal state. In total, about 45G has to be copied. There are some large files ~10G and some very small files such as .conf files that are only a few bytes large. I kept a small sleep window to give the system time to breath. This is the script I used : (/data is NFS mounted)
#!/bin/bash
for i in {1..20}
do
echo "run $i"
{ time rsync -avH --progress /data /data_store ; } > /tmp_info_rsync_$i 2> /tmp/time_e_rsync_$i
rm -rf /data_store/*
sleep 10
done
with N=20, the average in minutes :
real : 6,203
user : 5,281
sys : 2,394
Real is the time from start to finish, **user **is the amount of CPU time spent in user-mode code within the process. **Sys **is the amount of CPU time spend in system calls within the kernel, that where used in the process.[source]
tcp_sack disabled, no packet loss
Disabling tcp_sack can be adding to /etc/sysctl.conf
# disable tcp_sack, this is used to recover faster from dropped packages in high latency situations net.ipv4.tcp_sack = 0
Then reload using
sysctl -p
You can verify the status :
sysctl -a | grep tcp_sack net.ipv4.tcp_sack = 0
I ran the same script, to verify if _tcp_sack _had any influence on this workload. I ran this only 10 times, since you will see the results are very similar to the previous numbers. (read: I got bored waiting)
with N=10, the average in minutes :
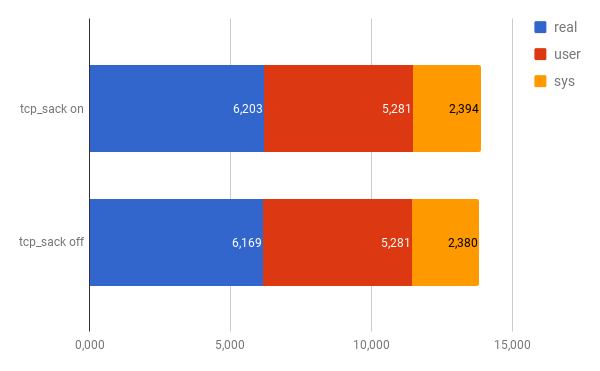
I don’t think any statistician would agree with the conclusion this is really faster the differences are to small, also the sample set to small. However, I do believe that there is some support for _tcp_sack _off to be a slightly faster compared to tcp_sack on. Straight from a Red Hat network performance tuning guide:
There is some research available in the networking community which shows enabling SACK on high-bandwidth links can cause unnecessary CPU cycles to be spent calculating SACK values, reducing overall efficiency of TCP connections. This research implies these links are so fast, the overhead of re-transmitting small amounts of data is less than the overhead of calculating the data to provide as part of a Selective Acknowledgment. Unless there is high latency or high packet loss, it is most likely better to keep SACK turned off over a high performance network.
Conclusion
Based on these results I don’t think putting tcp_sack on or off will significantly improve or deteriorate speed, in the conditions tested. Therefor I would recommend not touching these parameters. _tcp_sack _is linked to other features such as _tcp_dsack _and tcp_fack (see tcpvariables), so disabling it might have other consequences, however there are some switches that cannot (could not ?) handle tcp_sack. In that case it might be required to put tcp_sack off, which as shown won’t have a huge impact, in the tested conditions. So is tcp_sack a useless overhead ? I believe not.