
KeepAlive on or off ? Apache Tuning
Posted on February 4, 2016 • 8 minutes • 1544 words
Only recently I have been looking into optimization of webserver. In that search I have found some really low hanging fruit, such as keeping the byte-compiled PHP version of a file in memory, using Zend Opcache or the now deprecated APC. I even started thinking in some very unconventional ways, such as hybrid static rendered pages/blog. Only a few days ago I saw a presentation on HTTP/2, something until now, my brain had marked this as not applicable/uninterested/ignore until further notice. Yesterday however that changed, a presentation at ma.ttias.be boosted my interest for the lower level (for me) of how the http protocol worked and why there are so many version out there. Now I am no expert and not going to be one for some time, but what hooked me is the parameter Keep-Alive.
**Keep-Alive
** In technical terms Keep-Alive is a method to re-use a TCP connection. When a connection is created, the client, will send some setup value (SYN) to the server, who will respond with an acknowledgment (SYN ACK). This is done every time before a clients sends its requests to the server. While this in itself is only a small amount of the time, websites these days have a ton of resources (images, js, css, …) this might add up quit some requests each having to setup a connection. While in HTTP/1, it was strictly one resource one connection -unless defined otherwise in the header-, in 1999 a finalized HTTP/1.1 saw light, the major improvement was the addition of HTTP persistent connection (aka Keep-Alive) and HTTP pipelining. With Keep-Alive enabled on the server, a compatible client will continue to re-use the same connection for requests. This can be used to shave off some time spend in TCP connection setup.
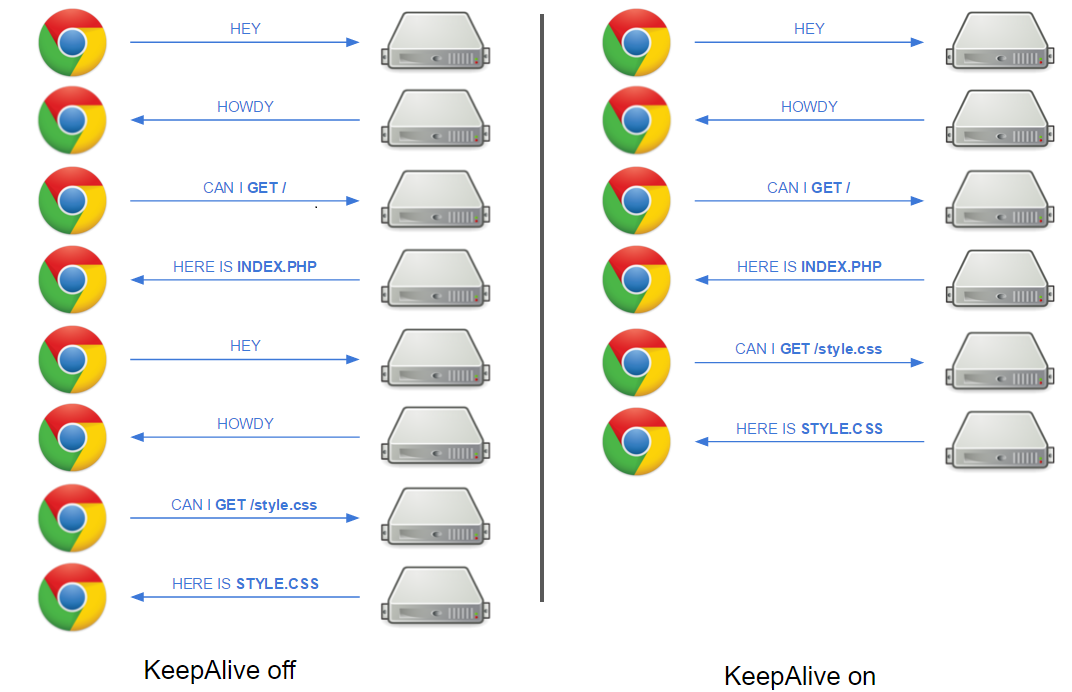
How much** time can I win with this ?
** Any speedup is always relative and will vary depending on allot of variables, many of which are out of your control. But to give an idea, I created a page with 20 CSS files and tested an Apache setup with KeepAlive on and off. I would expect (read:prediction), a speed increase equal to the ping time for each connection that is not needed because of Keep-Alive. Modern browsers will create 6-8 connections per domain to get the resources faster, independent if Keep-Alive is on or off (that is why people shard* btw).
There are 21 files to be downloaded (Index.html + 20CSS) That means that 7 browser connections would need to download 3 files each. So if all the resources are downloaded within the KeepAliveTimeout (I will get to that) That means that my Keep-Alive would require only 7 connections and my not Keep-Alive site 21. So in essence I win 14 TCP connections, at least if enough MaxKeepAliveRequests are available. (I also will get to that) Considering I need an extra roundtrip to the server for those 14 extra connections, a ping time would be a good indication. (I guess) Since I live rather close to my server I get ping times of around 10-20 ms, that would equal 2014 = ~280ms of speed gain. This is a huge amount on a static page time.
- sharding is the use of multiple domains, to trick the browser in using more parallel connections. (you would recognize this with links like cdn1.svennd.be, img.svennd.be, static.svennd.be, …)
The first test shows without Keep-Alive activated.
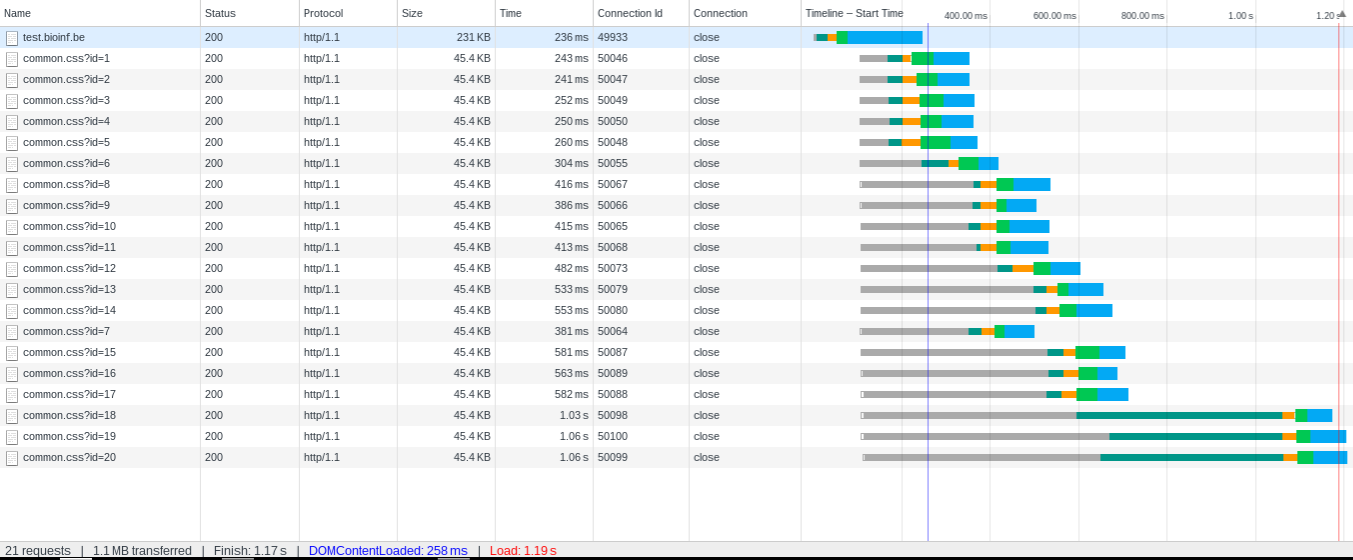 Keep-Alive off, clearly see the connection setup before each TTFB (time to first byte)
Keep-Alive off, clearly see the connection setup before each TTFB (time to first byte)
Now lets activate the Keep-Alive;
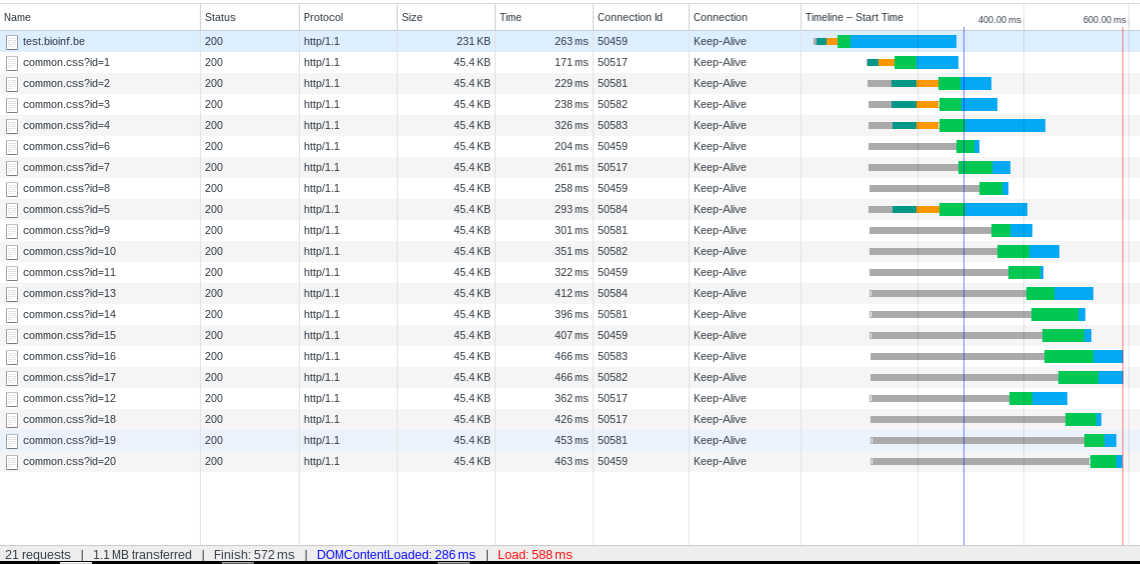 Clearly 6 connections do create the connection, all the other use the existing connections.
Clearly 6 connections do create the connection, all the other use the existing connections.
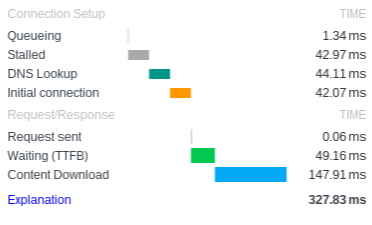
This is google’s chrome browser, but in case you don’t have this browser here is a overview of the colors :
Keep-Alive off : 1190 ms, Keep-Alive on : 588 ms, a speedup of 602 ms ! Now to be honest, I cherry picked this example, most requests for Keep-Alive off are ~800ms and the Keep-Alive on in are ~600ms. This is close to what I was expecting, around 200 ms gain. Obviously this was on a static example, dynamic pages will be slower and most likely bigger in size. Hence the % speedup will be a lot lesser.
**So what are the disadvantages ?
** The disadvantage of using Keep-Alive is quite simple, it uses resources that might not be required. When a connection is open on Apache all of the resources remain ready to “answer” even when there will never be another request. This is mostly memory wise a problem. For Apache memory has always been a bit of an issue, hence popularity of Nginx and the sorts. However, most guides will advise against using Keep-Alive when memory is tight, I’m not so sure that’s the best advice to give though. KeepAlive on Apache is restricted by a few settings (read below) that can be tuned to your use profile. Hence it is even be possible with little memory to use this speedup.
**Settings to tune
** The settings are located in /etc/httpd/conf.d/httpd.conf, for Centos (Fedora, Red Hat,…), although its advised to use the /etc/httpd/conf.d/ directory so that newer versions of httpd (aka Apache) don’t overwrite your config. For Debian and friends (Ubuntu, Mint, …) the file can be found at /etc/apache2/apache.conf. On a second note, make a backup of the config before editing. (this goes w/o saying, but these kind of tweaks are easily forgotten)
- **KeepAlive : **The main “flag”, in case you can spare the memory, I would advice to put it to on. On Debian this flag is on by default, on Centos its off by default. (might change in the future)
- **MaxKeepAliveRequests : **This is the setting of how many requests to allow, note that any modern browser will have 6 connections, so divide by 6 and this is the amount of visitors that will be able to use KeepAlive (concurrent). This option can be used to limit the resources the feature KeepAlive will utilize, but I would advice against using this as the limit unless you are forced. In my opinion its better to serve lesser users with KeepAlive then none at all.
- **KeepAliveTimeout : **by default the value of 15 seconds is used, to my opinion that is way, way to much. This means after the last resource has been downloaded the connection remains open for another 15 seconds (minus the time it was already open) and hence all resources remain in use. While there is an advantage to long KeepAliveTimeout (next page), I don’t think most situations require this. A personal rule of thumb is, how long does it take for an average page to loads. For example when the page loads for 5 seconds, a timeout of less then 5 would be more then enough. While a longer timeout would speed up a next page of your visitor, its uncertain that a user will a) continue on your website b) reads the page and continues within 15 seconds. The chance that a user would wanne download your CSS is allot higher. Hence I think in most situations a good balance would be to put the timeout not larger then 2-3 seconds. If the page takes longer then 2/3 seconds, don’t waste your time with this tuning, fix your application first.
**When to not use Keep-Alive
**
- You have to little memory and you are searching to lower memory usage.
- You have a static html website with little to none external resources, such as javascript, images, css, …
- You think people should be patient and wait 280ms longer.
When to use Keep-Alive
- You have enough memory under free -m
- You have times where there is low usage, and then you wanne server users ASAP.
- The website was build post 2000 hence it has JavaScript, css, images, fonts, xml, …
- Every 200ms is less waiting, is more productivity.
**How to edit
** This is only an example, edit as you test. File to edit (on centos) : /etc/httpd/conf.d/httpd.conf
# put it on KeepAlive On # /6 this would be 20 concurrent visitors (Timeout window concurrent) MaxKeepAliveRequests 120 # keep connections open 2 seconds KeepAliveTimeout 2
Example configurations
You have a VPS with limited memory (512 Mb, 1Gb) and visitors don’t come in one clear peak.
KeepAlive On # allow 50 users to use requests MaxKeepAliveRequests 300 # keep connections open for 1 seconds KeepAliveTimeout 1
If you have no problems : increase KeepAliveTimeout; If you have problems : decrease MaxKeepAliveRequests.
You have a dedicated server with allot of memory (you have “free” memory under free -m) and visitors come in peaks.
KeepAlive On # allow 50 users to use requests MaxKeepAliveRequests 300 # keep connections open for 5 seconds KeepAliveTimeout 5
If you have no problems : increase MaxKeepAliveRequests, unless your website only pulls ~50 users. If you have problems decrease KeepAliveTimeout to 2-3 seconds, if it remains a problem decease MaxKeepAliveRequests.
Conclusion
Keep-Alive can help you speed up your website by quite some time, but its not a magical switch, there are consequences to using it, although I think these can be for a large part be circumvented if suited settings are used. It is interesting to see that in HTTP/2 both Keep-Alive and HTTP pipelining are on by default, in fact they are part of the protocol.